반응형
프로젝트 팀 명 : b1a4
수업 일자 : 2025. 09. 22
성명 : 김도이
나의 프로젝트 수업 점수 : / 100
오늘 할 일
- [x] b1a4 Organization 레벨에서 백엔드/프론트엔드 Project (Sprint 1) 생성
- [x] backend/README.md 파일 작성 > PR
- [ ] DB
- [x] 1.개념적설계 : 현실세계에서 관리해야 할 개체(Entity)와 관계를 정의 (예: 회원 ↔ 주문 ↔ 상품)
- [ ] 2.논리적설계(ERD모델링) : 개념적 설계를 기반으로 ERD를 작성 / 엔티티, 속성, 관계 카디널리티(1:1, 1:N, N:M)를 명확히
- [ ] 3.물리적설계(테이블) : ERD를 실제 DBMS에 맞게 변환 / 테이블명, 컬럼명, 데이터타입, PK/FK, 제약조건, 인덱스까지 반영
- [x] API 명세서 완성
- [x] 백엔드 역할분담
- [ ] MVP란?
- [ ] TIL 작성하기
1) 프로젝트 수업에서 배운점
- ON DELETE SET NULL
- ON DELETE CASCADE : 부모 레코드 삭제 → 자식 레코드도 자동 삭제
- 예) 유저를 삭제하면 그 유저의 리뷰, 댓글 전부 같이 삭제
- ON DELETE SET NULL : 부모 레코드 삭제 → 자식 테이블의 외래키 값을 NULL로 바꿈
- 예) 카페가 삭제되면 그 카페를 참조하는 채팅방(chatroom)의 cafe_id가 NULL 처리됨
- 전제조건: 해당 외래키 컬럼이 NULL 허용이어야 함 (NOT NULL 이면 에러남)
- ON DELETE CASCADE : 부모 레코드 삭제 → 자식 레코드도 자동 삭제
- UUID vs AUTO_INCREMENT (INT PK)
- AUTO_INCREMENT : DB가 1,2,3… 순서대로 PK 값을 자동 생성. 사람 눈에 보기 쉽고 직관적
- UUID (Universally Unique Identifier) : 전역적으로 유일한 128bit 값. 사람이 보기에는 긴 문자열처럼 보임
- 장점: 분산 시스템에서 충돌 없이 UNIQUE KEY를 생성 가능, DB merge 시에도 충돌 위험 ↓
- 단점: 인덱스 크기 커짐(성능 약간 불리), 숫자보다 길어서 관리 불편
- MySQL 에서 UUID 생성 방법
- SQL 내장 함수: SELECT UUID(); → '550e8400-e29b-41d4-a716-446655440000' 같은 값 생성
- 애플리케이션 코드단(Java, Node.js 등)에서 UUID 라이브러리 사용 후 insert할 때 PK로 전달
- MySQL 8 이상에서는 UUID_TO_BIN(), BIN_TO_UUID() 써서 이진형(16Byte)으로 저장하면 성능 이점 있음
- bigserial (MySQL에서는 안 씀)
- PostgreSQL 전용 타입. MySQL에서는 BIGINT AUTO_INCREMENT가 대응되는 개념
- 즉, 큰 정수(8Byte) 자동 증가 PK 만들 때 MySQL은 BIGINT AUTO_INCREMENT를 쓰면 됨
- INT (4Byte-32bit 정수) : -2,147,483,648 ~ 2,147,483,647
- BIGINT (8Byte-64bit 정수) : -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,207
- 초대형서비스에서 PK 값이 20억을 넘어갈 가능성 있을 때 사용
- 예) SNS 댓글, 로그성 데이터, IoT 센서 데이터 등 기록이 수십억 건 이상 쌓이는 시스템
- 초대형서비스에서 PK 값이 20억을 넘어갈 가능성 있을 때 사용
- 언제 BIGINT를 써야 하나?
- 트래픽이 엄청 많은 글로벌 서비스처럼 데이터가 수십억~수십조 건 이상 될 경우
- 이미 INT 범위를 초과할 가능성이 예상되는 테이블 (예: 채팅 메시지, 클릭 로그 등)
- 반대로, 대부분의 스타트업·중소 규모 서비스라면 INT로도 충분하고, BIGINT는 DB크기/인덱스 크기만 불필요하게 커질 수 있음
- double **precision** (경도, 위도)
- MySQL에는 DOUBLE 또는 FLOAT 타입 있음
- FLOAT : 4Byte, 정밀도 약 7자리
- DOUBLE : 8Byte, 정밀도 약 15~16자리
- 위도(latitude), 경도(longitude)는 소수점 6자리 이상 필요 → 위치좌표는 보통 DOUBLE 씀
- 예) 서울 37.566295, 126.977945 → FLOAT이면 오차 큼 → DOUBLE이 안전
- PRECISION (정밀도) / SCALE (스케일)
- PostgreSQL 에서, 숫자 타입에서 **얼마나 많은 자릿수(precision)**와 **소수점 이하 몇 자리(scale)**를 저장할 지 지정하는 옵션 - 데이터타입 정의에 붙는 옵션
- 예시
- DECIMAL(10,2) → 총 10자리 중 소수점 이하 2자리 → 12345678.90 저장 가능
- FLOAT, DOUBLE은 MySQL 8.0 이상에서 FLOAT(precision) 옵션은 사실상 무시되고, 그냥 크기(4Byte, 8Byte)로만 동작
- MySQL에서는 그냥 DOUBLE과 동일함 (DOUBLE PRECISION 써도 똑같이 처리됨)
- MySQL에는 DOUBLE 또는 FLOAT 타입 있음
- jsonb (Postgres 용어) → MySQL에서는 JSON
- MySQL 5.7 이상에서는 JSON 타입 제공 (Postgres의 JSONB와 비슷)
- 특징
- 구조화된 JSON 데이터를 DB컬럼에 그대로 저장 가능
- 예) open_hours, menu, photos 같은 건 카페마다 다 다르고 스키마 고정하기 애매 → JSON 컬럼이 유연함
- MySQL에서 쿼리 시 JSON 함수 (JSON_EXTRACT, ->, ->>)로 데이터 뽑을 수 있음
- JSON 값에서 특정 경로의 데이터를 꺼내옴
(2) -> 연산자 (JSON_EXTRACT 단축형)SELECT JSON(EXTRACT('{"a": 10, "b": {"c": 20}}, $b.c')); -- 결과: 20- JSON 컬럼에서 값을 뽑음
(3) ->> 연산자 (JSON_UNQUOTE + JSON_EXTRACT)SELECT json_column->'$.menu[0].name' FROM cafe;- 값을 문자열로 바로 가져옴 (따옴표 제거)
(4) JSON 수정 관련 함수SELECT json_column->>'$.menu[0].name' FROM cafe;- JSON_SET() : 기존 JSON에 key/value 추가 또는 수정
- JSON_REMOVE() : 특정 key 제거
- JSON_ARRAY_APPEND() : 배열에 값 추가
UPDATE cafe SET open_hours = JSON_SET(open_hours, '$.holiday', 'closed') WHERE id = 1; - (1) JSON_EXTRACT()
- 구조화된 JSON 데이터를 DB컬럼에 그대로 저장 가능
- 복합키(Composite Primary Key)
- 정의 : PK를 두 개 이상 컬럼 조합으로 설정하는 것 (여러 컬럼을 합쳐 PK. 특정 조합을 유일하게 보장할 때 사용)
- PRIMARY KEY (user_id, cafe_id)
- 의미
- 같은 유저가 같은 카페를 여러 번 withlist에 넣는 건 불가능 → user_id + cafe_id 조합이 UNIQUE 해야 함(중복 방지)
- 하지만 다른 유저는 같은 카페를 wishlist에 넣을 수 있음
- 장점
- 별도의 id(pk)컬럼 안 만들고, 실제 비즈니스 규칙을 그대로 PK에 반영
- 무의미한 surrogate key를 만들지 않아도 됨
- 테이블의 행(row)을 구분하기 위해 인위적으로 만든 의미없는 키
- 보통 자동 증가 숫자(INT AUTO_INCREMENT)UID 같은 값이 여기에 해당해요, 또는 U
- 데이터 자체와는 의미가 없고, 단순히 “고유 식별자” 역할만 합니다.
(2) Natural Key (자연 키)CREATE TABLE user ( id BIGINT AUTO_INCREMENT PRIMARY KEY, -- id는 순전히 식별용 surrogate key email VARCHAR(255) UNIQUE NOT NULL, -- 실제 의미 있는 값 ... );- 원래 데이터 자체에서 유일성을 보장할 수 있는 컬럼을 PK로 쓰는 경우
- 예) 주민등록번호, 이메일 주소, 학번, ISBN 등
- 이 경우 별도 surrogate key 없이도 구분이 가능
- Natural key는 현실에서 변할 수도 있음 (예: 이메일 바꾸기, 전화번호 바꾸기)
- PK는 변하지 않는 게 안정적 → surrogate key 도입
- join 성능 : surrogate key(INT, BIGINT)는 짧고 인덱스 효율적이라 join 성능 유리
- 유연성 : 비즈니스 규칙이 바뀌어도 surrogate key는 그대로 두고 나머지만 수정 가능
- join 성능 : surrogate
- (1) Surrogate Key (대리 키)
- 단점
- FK 관계나 join 시 키가 길어짐
- 나중에 테이블 확장할 때 단순 정수 PK보다 불편할 수 있음
- GitHub Projects
2) 프로젝트 수업에서 느낀점
- DB 설계에서 TINYINT 와 VARCHAR 를 둘 다 사용할 수 있는 경우, 어떤 것을 고르는 것이 좋을까? 에 대해 고민했다.
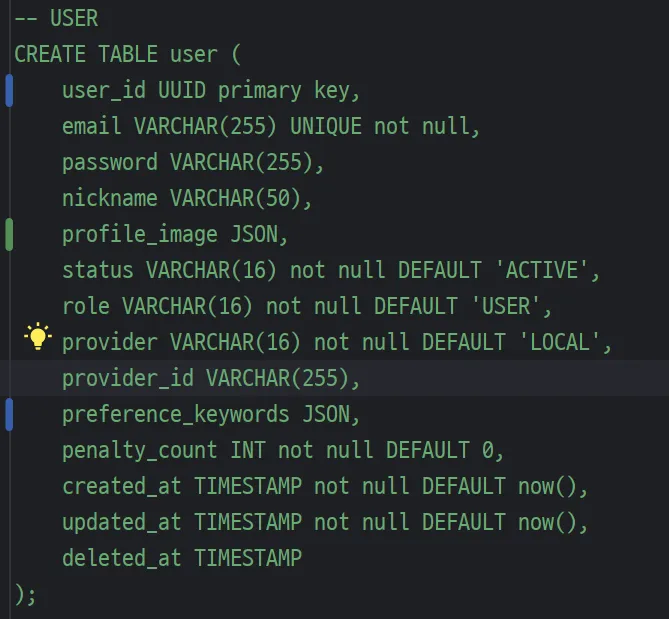
내가 작성한 것 
- 션 리더님께서 - TINYINT로 선언하는 것을 선호합니다.
- 보통 권한같은 경우에는 숫자값 비교를 통해 최고권한 > 그다음수준의 권한 > 다다음수준의 권한 이렇게 차이를 두다보니 비교하기가 쉬워서 TINYINT 를 쓸 때가 많았다고 하셨다.
- 근데!!!!! 우리는 최종적으로 ENUM으로 하기로 했다~ 아무래도 직관적으로 무슨 상태인지 문자열로 확인하는 게 여러모로 안 헷갈릴 것 같기도 하고, 숫자형태도 동시에 사용할 수 있으니!
3) 프로젝트 수업에서 실천할 점
- 부캠 와서 뿐만이 아니라 집에서도, 안 오는 날도 열심히 공부하고 적용해야 할 것 같다. 지난 프로젝트보다 생각보다 빡세고 타이트하게 진행해야 할 것 같다.
다음 할 일
- [ ] 크롤링 공부
- [ ] AI활용 - 어디까지가 가능한 기능인지 확인 필요
- [ ] 필요한 API들 둘러보기
'2025 > [풀스택]SeSAC 웹개발자 7기' 카테고리의 다른 글
| python 크롤링? (1) | 2025.10.01 |
|---|---|
| 관리자만 접근 가능한 인가 설정하기 (0) | 2025.09.26 |
| [BookTalk 팀프로젝트 회고모음] 험난했던 1달반의 여정을 마치며... KPT, TIL, CSS, ARR 회고 모음 (0) | 2025.09.10 |
| [TIL] DTO vs VO? (0) | 2025.08.25 |
| [TIL] API, REST, REST API, REST규칙? (0) | 2025.08.25 |